This notebook contains an example of two feature attribution methods applied to a PyTorch model predicting fuel efficiency for the Auto MPG Data Set.
We use the following methods:
- Integrated Gradients from the Captum package
- A custom toy implementation of the SHAP algorithm (Shapley values)
Attribution methods are applied per sample. As a result, each feature is assigned a value reflecting its contribution to the model's output — or, more precisely, to the difference between the model's output for the sample and the expected value.
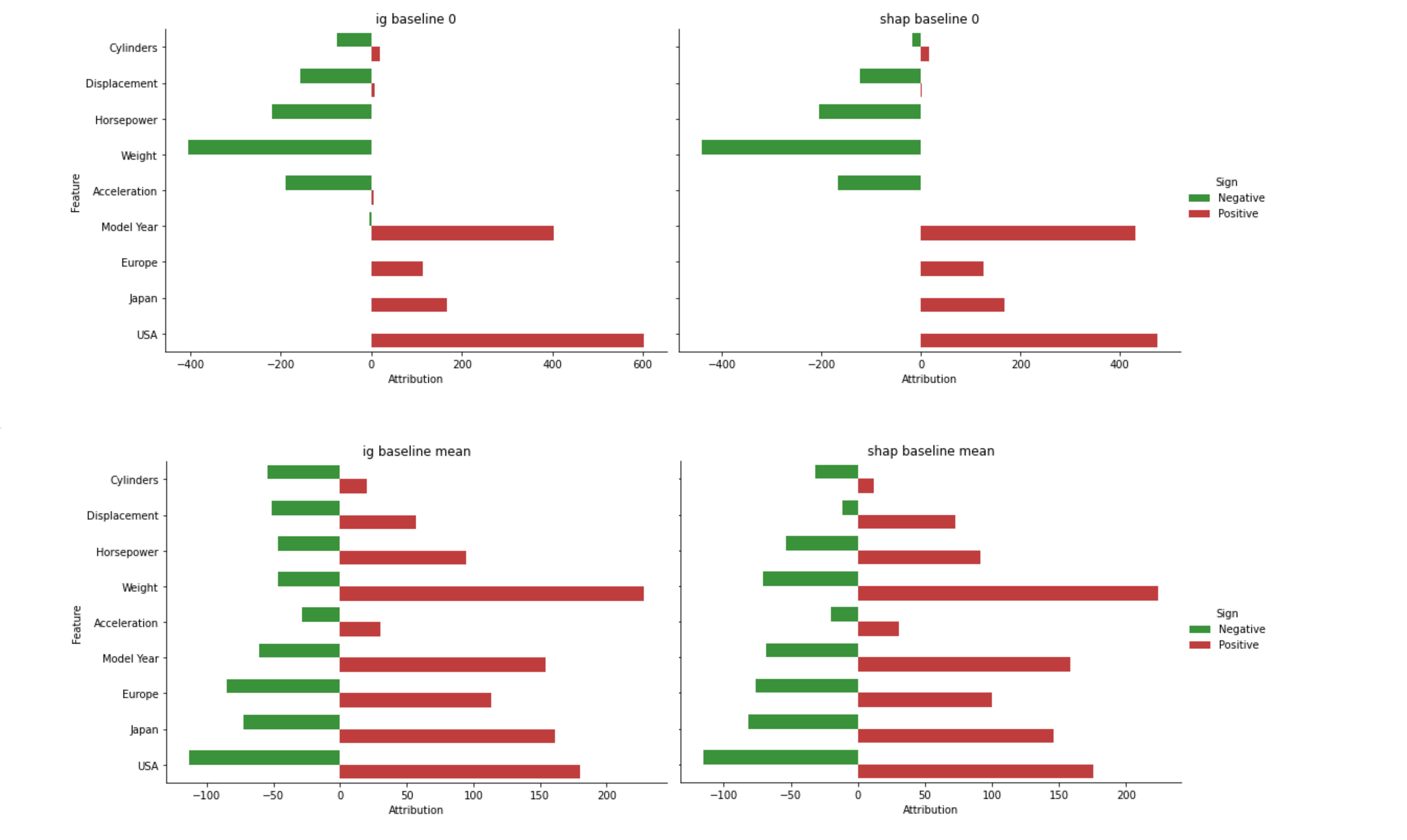
Both methods require setting a baseline: a vector of values that will be used, for each feature, in place of a missing value. The baseline serves as a set of reference values that can be thought of as neutral. We compute the expected value as the model's output for a selected baseline.
All attributions together account for the difference between the model's prediction for a sample and the expected value of the model's output for a selected baseline.
In the examples below we consider various baselines and see how they influence the importance assigned to each feature. For each sample, attributions sum to the difference between the model's output for the sample and the expected value (the model's output for the baseline used to compute attributions).
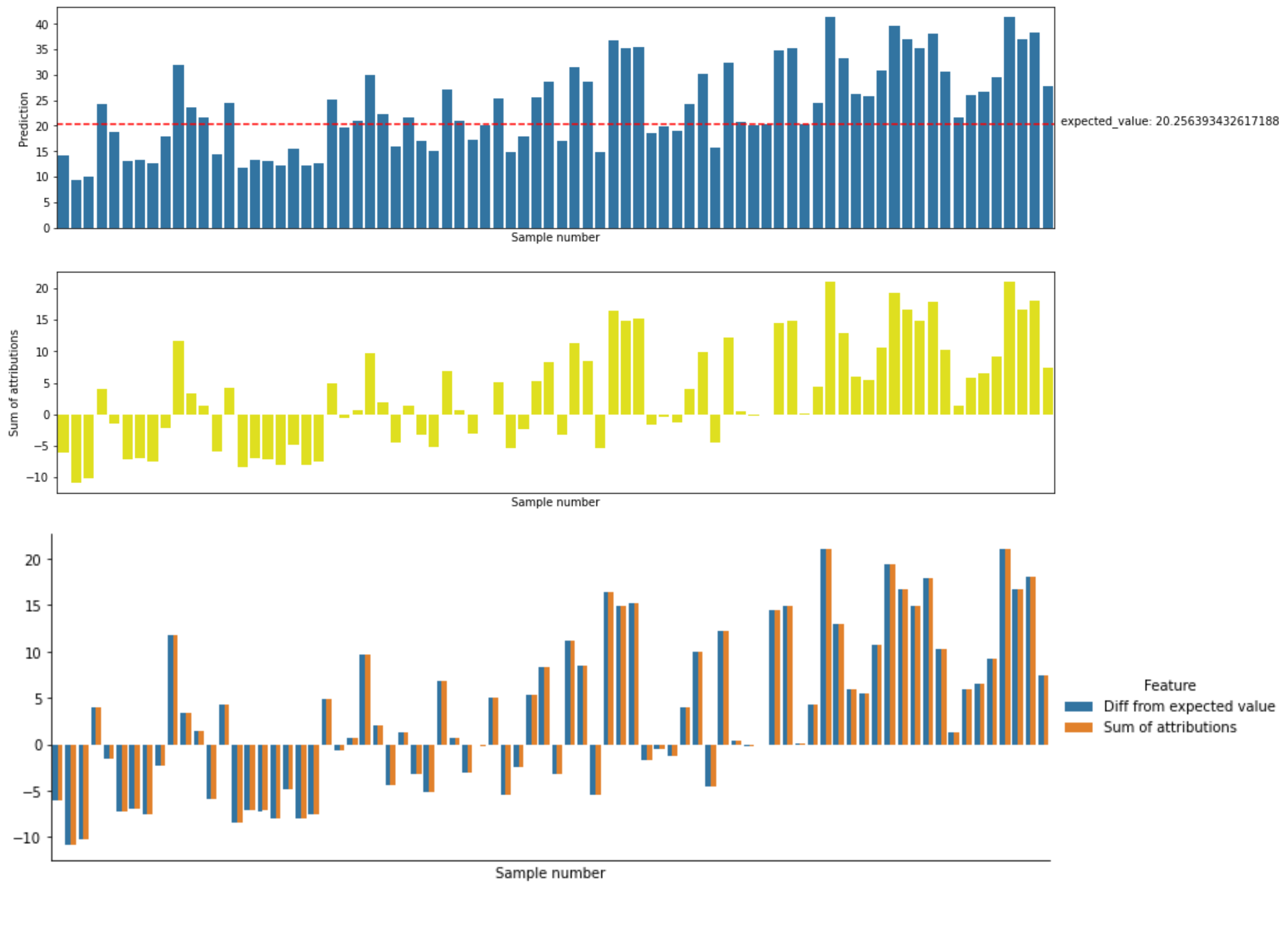
Attributions explain prediction
Attributions sum to the difference between the model's output and the expected value (the model's output for the baseline vector).
Features and attributions
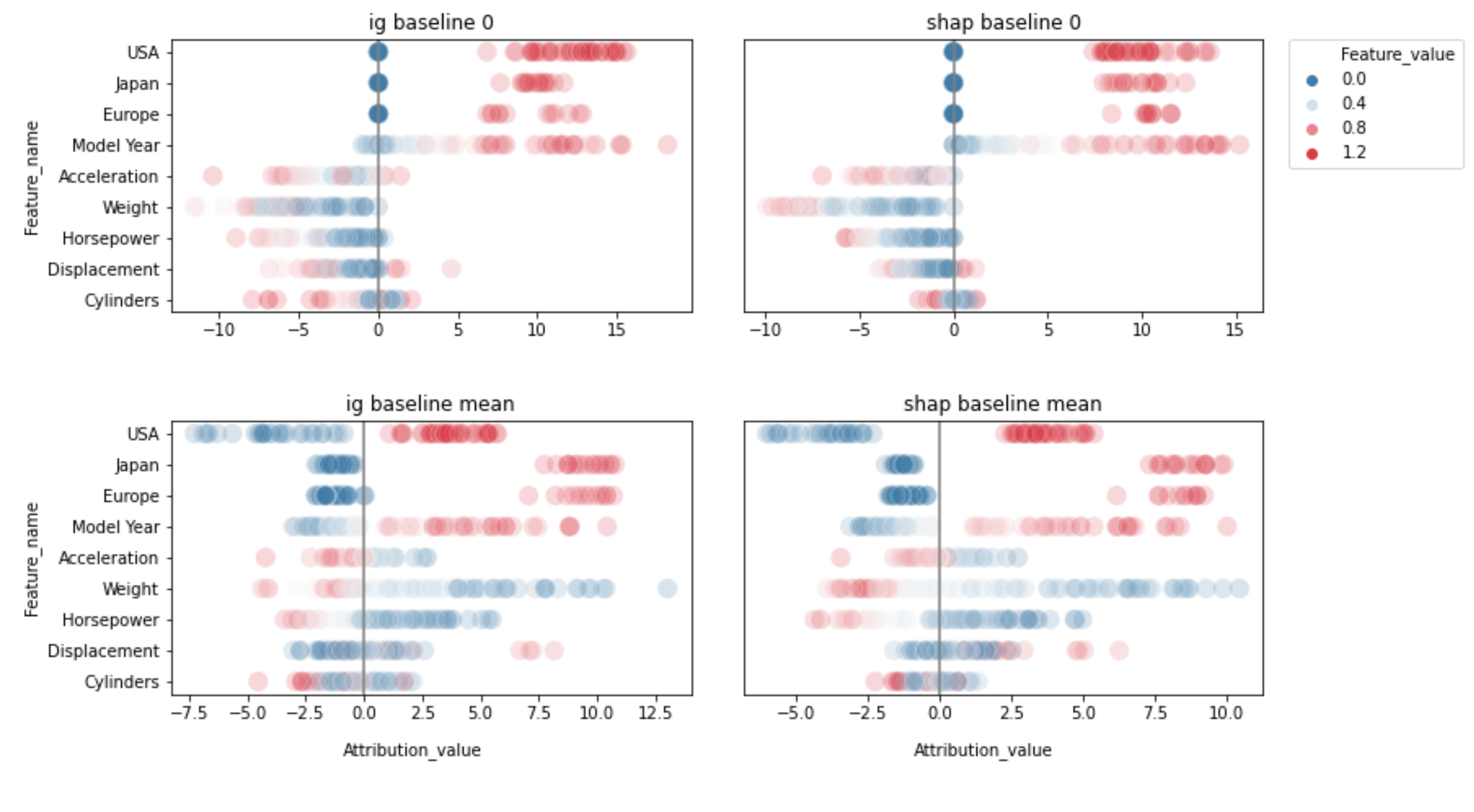
The diagrams show how high and low values of features are distributed across the range of attributions assigned by IG and SHAP for various baselines. For some features, high values (in red) correlate with high attributions on the x-axis; for others, they gather in the lower range or show no clear correlation.
Impact of features
Accumulated feature importance varies more between baselines than between attribution methods. One intuitive explanation: since both methods use a baseline to stand for a missing value, features with a near-monotonic relationship to the target are more consistently attributed a higher absolute impact when replaced by zero.