A TensorFlow 2 implementation of Adversarial Autoencoder (ICLR 2016).
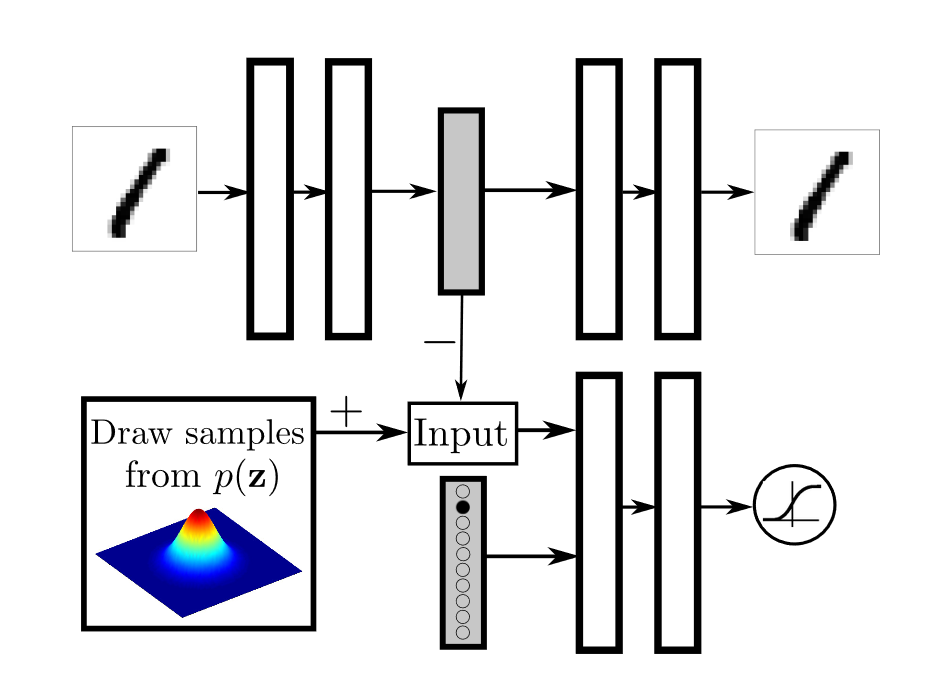
Model
Regularisation of the hidden code by incorporating full label information. The encoder learns a latent code that the discriminator pushes toward a chosen prior conditioned on the class label.
Fig. 3 from Alireza Makhzani, Jonathon Shlens, Navdeep Jaitly, Ian J. Goodfellow. Adversarial Autoencoders. CoRR abs/1511.05644 (2015).
Results for the gaussian_mixture prior
Latent space



Reconstruction


Training loss
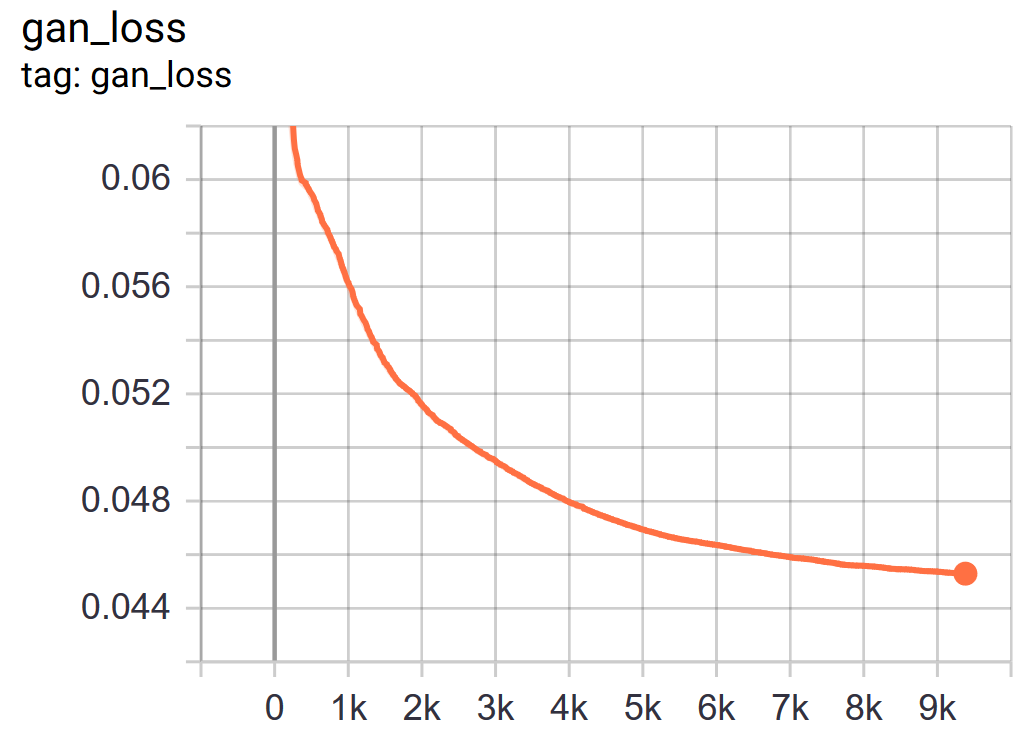
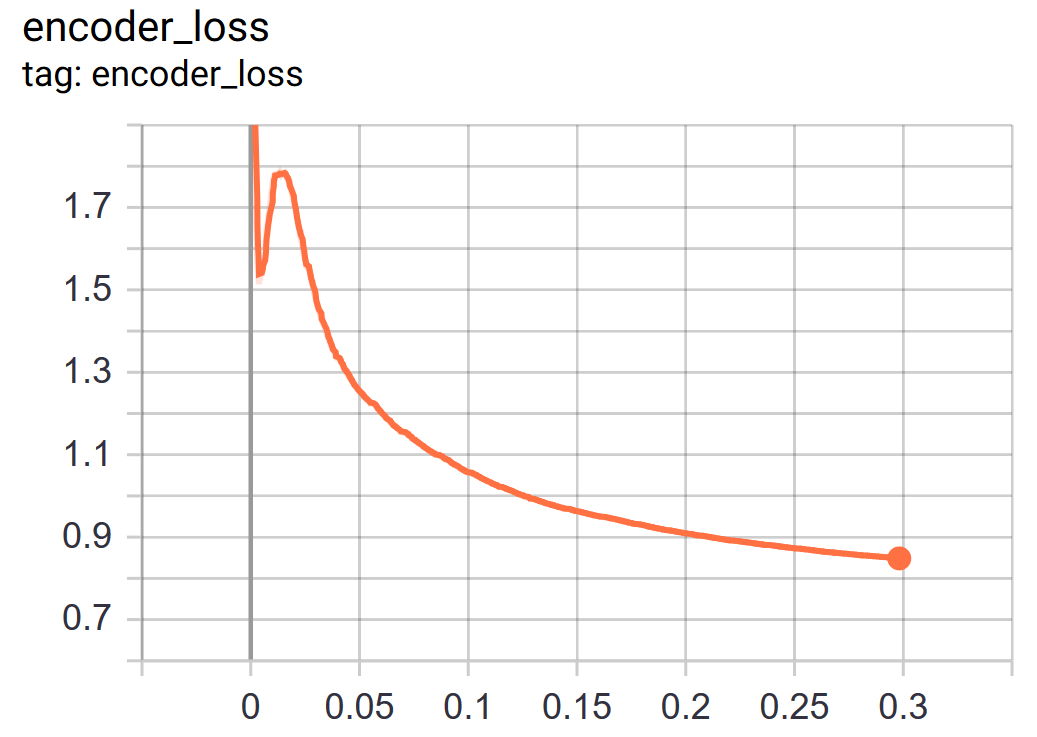
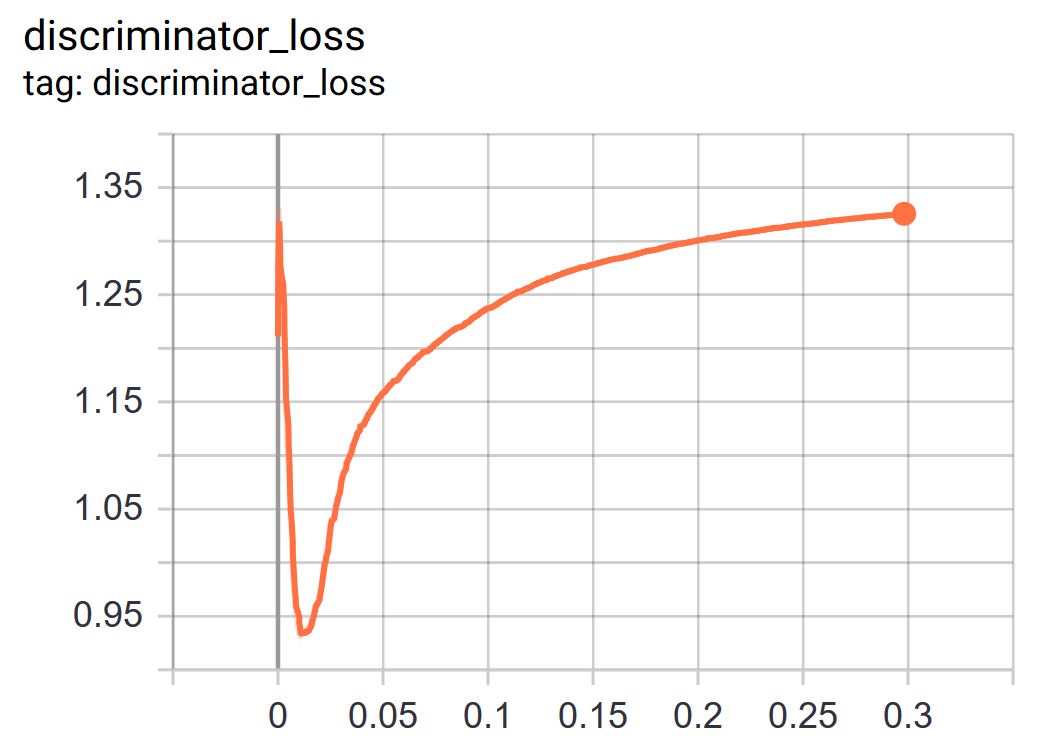
Example of usage
python train_model.py --prior_type gaussian_mixtureAttributes
--prior_type: target prior distribution. Default:gaussian_mixture. Required.--results_dir: training visualisation directory. Default:results. Created if non-existent.--log_dir: log directory (TensorBoard). Default:logs. Created if non-existent.--gm_x_stddev: Gaussian mixture prior, standard deviation for the x coord. Default:0.5--gm_y_stddev: Gaussian mixture prior, standard deviation for the y coord. Default:0.1--n_epochs: number of epochs. Default:20--learning_rate: learning rate. Default:0.001--batch_size: batch size. Default:128--num_classes: number of classes (for further use). Default:10
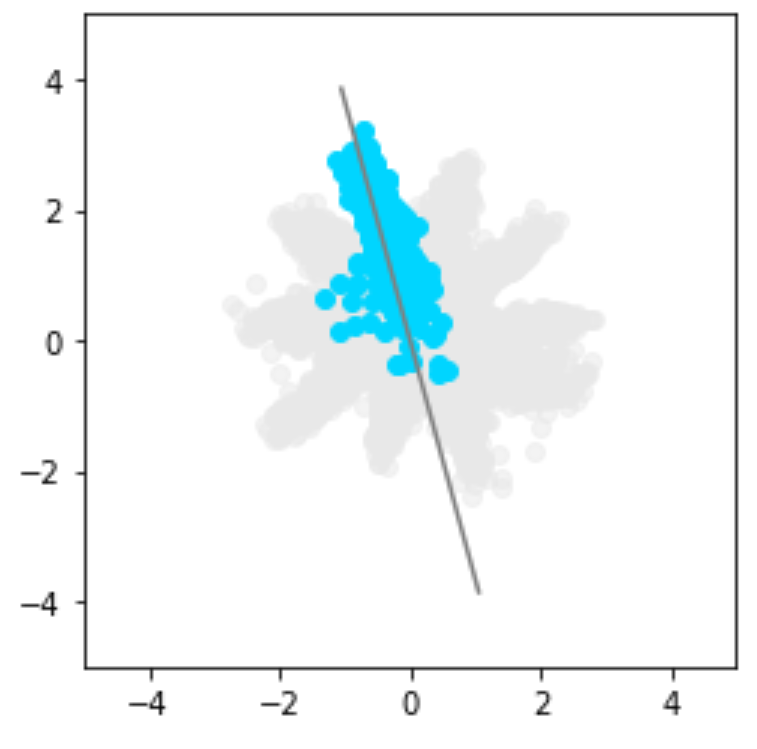
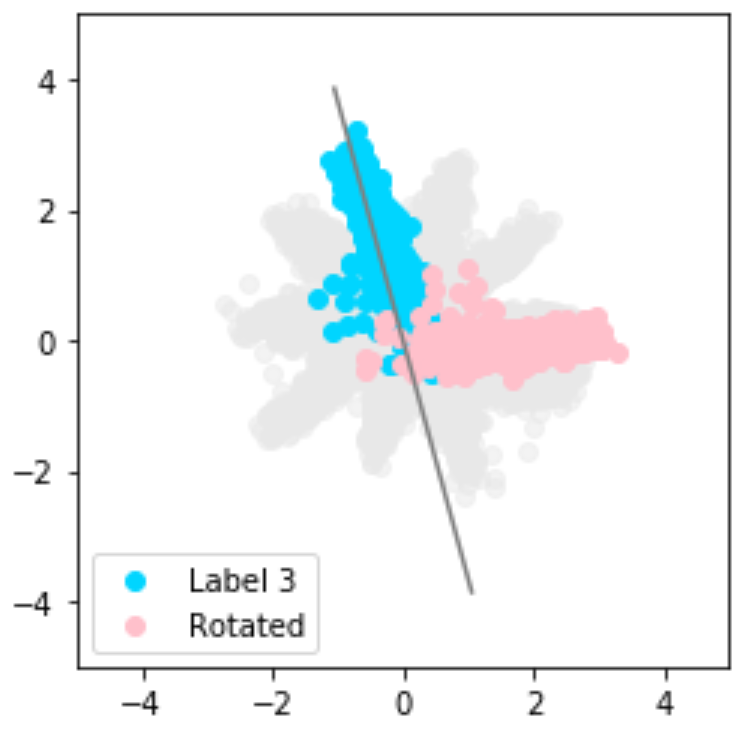
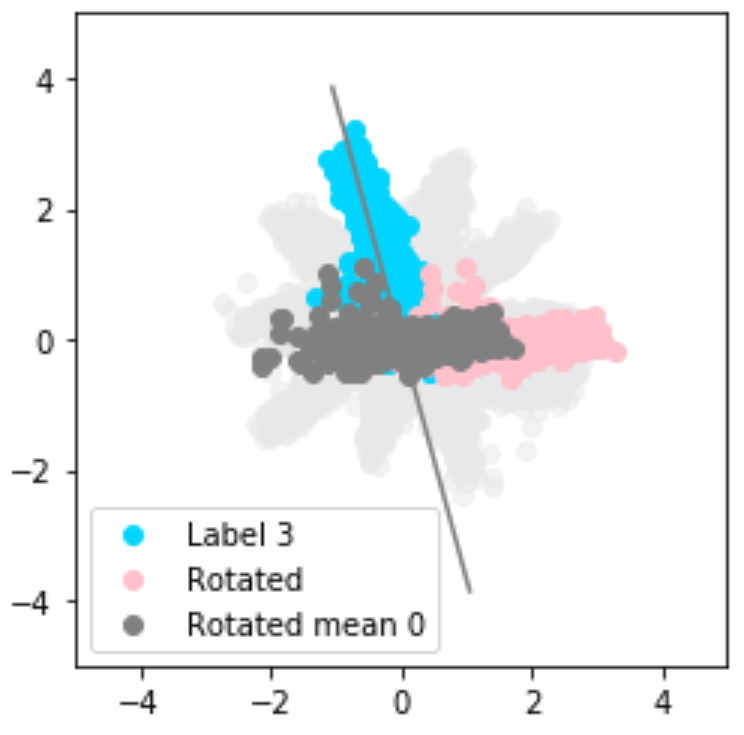
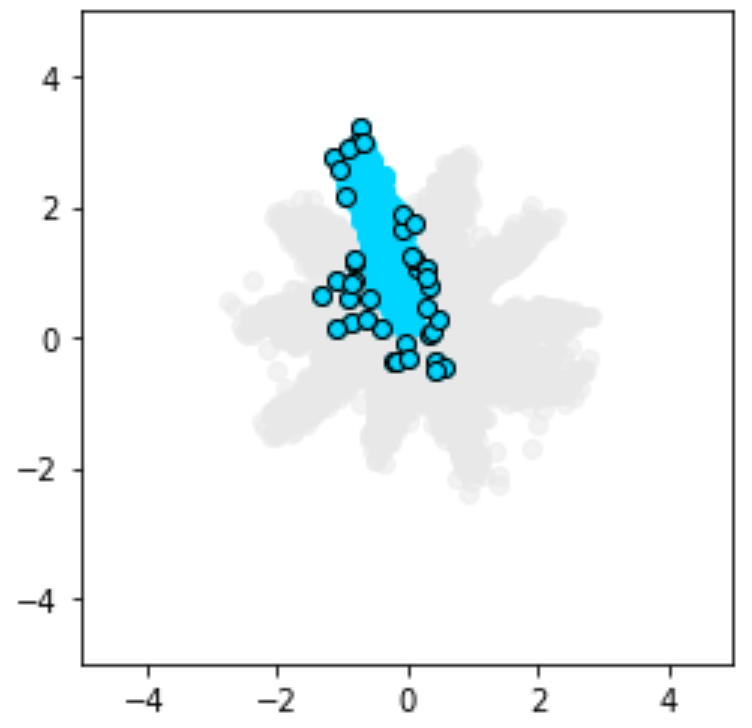
Visualisation of outliers
The encoder learns to map inputs into the latent space. By projecting those learnt representations with PCA, samples that fall outside the target Gaussian-mixture distribution can be surfaced as outliers — even when their reconstruction loss looks acceptable.
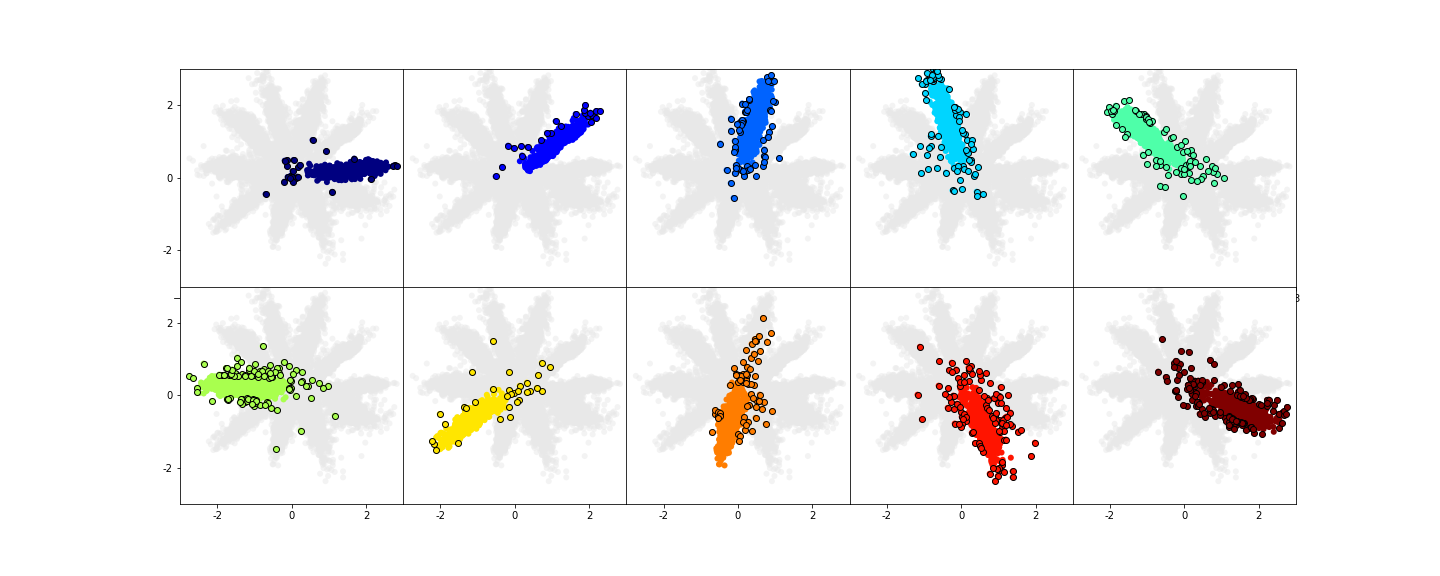
Detecting outliers in the latent space with PCA